AWS Serverless Lambda Scheduled Events to Store Tweets in Couchbase explained how to store tweets in Couchbase using AWS Serverless Lambda. Now, this Lambda Function has been running for a few days and has collected 269 tweets from @realDonaldTrump. This blog , inspired by SQL on Twitter: Analysis Made Easy Using N1QL, will show how these tweets can be analyzed using N1QL.

N1QL is a SQL-like query language from Couchbase that operates on JSON documents. N1QL and SQL Differences provide differences between N1QL and SQL. Let’s use N1QL to reveal some interesting information from @realDonaldTrump‘s tweets.
Many thanks to Sitaram from N1QL team to help hack the queries.
How Many Tweets
First query is to find out how many tweets are available in the database. The query is pretty simple:
Query:
|
|
SELECT COUNT(*) tweet_count
FROM twitter;
|
As you notice, the syntax is very similar to SQL. SELECT, COUNT and FROM clauses are what you are already familiar with from SQL syntax. tweet_count is an alias defined for the returned result. twitter is the bucket where all the JSON documents are stored.
Results:
|
|
[
{
"tweet_count": 269
}
]
|
The result is a JSON document as well.
Tweet Sample JSON Document
In order to write queries on a JSON document, you need to know the structure of the document. The next query will give you that.
Query:
|
|
SELECT *
FROM twitter
LIMIT 1;
|
The new clause introduced here is LIMIT. This allows to restrict the number of objects that are returned in a result set of SELECT.
Results:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
[
{
"twitter": {
"accessLevel": "0",
"contributors": [],
"createdAt": "1480828438000",
"currentUserRetweetId": "-1",
"displayTextRangeEnd": "-1",
"displayTextRangeStart": "-1",
"favoriteCount": "116356",
"favorited": false,
"geoLocation": null,
"hashtagEntities": [],
"id": "805278955150471168",
"inReplyToScreenName": null,
"inReplyToStatusId": "-1",
"inReplyToUserId": "-1",
"lang": "en",
"mediaEntities": [],
"place": null,
"possiblySensitive": false,
"quotedStatus": null,
"quotedStatusId": "-1",
"rateLimitStatus": null,
"retweet": false,
"retweetCount": "28330",
"retweeted": false,
"retweetedByMe": false,
"retweetedStatus": null,
"scopes": null,
"source": "<a href=\"http://twitter.com/download/android\" rel=\"nofollow\">Twitter for Android</a>",
"symbolEntities": [],
"text": "Just tried watching Saturday Night Live - unwatchable! Totally biased, not funny and the Baldwin impersonation just can't get any worse. Sad",
"truncated": false,
"urlentities": [],
"user": {
"accessLevel": "0",
"biggerProfileImageURL": "http://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_bigger.jpg",
"biggerProfileImageURLHttps": "https://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_bigger.jpg",
"contributorsEnabled": false,
"createdAt": "1237383998000",
"defaultProfile": false,
"defaultProfileImage": false,
"description": "President-elect of the United States",
"descriptionURLEntities": [],
"email": null,
"favouritesCount": "46",
"followRequestSent": false,
"followersCount": "19294404",
"friendsCount": "42",
"geoEnabled": true,
"id": "25073877",
"lang": "en",
"listedCount": "52499",
"location": "New York, NY",
"miniProfileImageURL": "http://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_mini.jpg",
"miniProfileImageURLHttps": "https://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_mini.jpg",
"name": "Donald J. Trump",
"originalProfileImageURL": "http://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2.jpg",
"originalProfileImageURLHttps": "https://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2.jpg",
"profileBackgroundColor": "6D5C18",
"profileBackgroundImageURL": "http://pbs.twimg.com/profile_background_images/530021613/trump_scotland__43_of_70_cc.jpg",
"profileBackgroundImageUrlHttps": "https://pbs.twimg.com/profile_background_images/530021613/trump_scotland__43_of_70_cc.jpg",
"profileBackgroundTiled": true,
"profileBannerIPadRetinaURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/ipad_retina",
"profileBannerIPadURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/ipad",
"profileBannerMobileRetinaURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/mobile_retina",
"profileBannerMobileURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/mobile",
"profileBannerRetinaURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/web_retina",
"profileBannerURL": "https://pbs.twimg.com/profile_banners/25073877/1479776952/web",
"profileImageURL": "http://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_normal.jpg",
"profileImageURLHttps": "https://pbs.twimg.com/profile_images/1980294624/DJT_Headshot_V2_normal.jpg",
"profileLinkColor": "0D5B73",
"profileSidebarBorderColor": "BDDCAD",
"profileSidebarFillColor": "C5CEC0",
"profileTextColor": "333333",
"profileUseBackgroundImage": true,
"protected": false,
"rateLimitStatus": null,
"screenName": "realDonaldTrump",
"showAllInlineMedia": false,
"status": null,
"statusesCount": "34269",
"timeZone": "Eastern Time (US & Canada)",
"translator": false,
"url": "https://t.co/mZB2hymxC9",
"urlentity": {
"displayURL": "https://t.co/mZB2hymxC9",
"end": "23",
"expandedURL": "https://t.co/mZB2hymxC9",
"start": "0",
"text": "https://t.co/mZB2hymxC9",
"url": "https://t.co/mZB2hymxC9"
},
"utcOffset": "-18000",
"verified": true,
"withheldInCountries": null
},
"userMentionEntities": [],
"withheldInCountries": null
}
}
]
|
Top 5 Tweeting Days
After the basic queries are out of the way, let’s look at some interesting data now.
What are the top 5 days on which @realDonaldTrump tweeted and the tweet count?
Query:
|
|
SELECT SUBSTR(MILLIS_TO_STR(TO_NUM(createdAt)), 0, 10) tweet_date,
COUNT(1) tweet_count
FROM twitter
GROUP BY SUBSTR(MILLIS_TO_STR(TO_NUM(createdAt)), 0, 10)
ORDER BY COUNT(1) DESC
LIMIT 5;
|
Usual GROUP BY and ORDER BY SQL clauses perform the same function.
N1QL Functions apply a function to values. The createdAt field is returned a number as a String. TO_NUM function converts the String to a number. MILLIS_TO_STR function converts the String to a date. Finally, SUBSTR function extracts the relevant part of the date.
Results:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
[
{
"tweet_count": 13,
"tweet_date": "2017-01-17"
},
{
"tweet_count": 12,
"tweet_date": "2017-01-06"
},
{
"tweet_count": 11,
"tweet_date": "2016-12-04"
},
{
"tweet_count": 10,
"tweet_date": "2017-01-03"
},
{
"tweet_count": 10,
"tweet_date": "2017-01-04"
}
]
|
Jan 17th, 2017 is the most tweeted day. Now, this result is of course restricted to the data from the JSON documents stored in the database.
Does anybody have a more comprehensive database of @realDonaldTrump tweets?
Tweet Frequency
OK, our database shows that that maximum number of tweets in a day were 13. How do I find out how many days @realDonaldTrump tweeted a certain number of times?
Query:
|
|
SELECT a.tweet_count, count(1) days FROM (
SELECT SUBSTR(millis_to_str(to_num(createdAt)), 0, 10) tweet_date,
COUNT(1) tweet_count
FROM twitter
GROUP BY SUBSTR(millis_to_str(to_num(createdAt)), 0, 10)
) a
GROUP BY a.tweet_count
ORDER BY a.tweet_count DESC;
|
This is easily achieved using N1QL nested queries.
Results:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
[
{
"days": 1,
"tweet_count": 13
},
{
"days": 1,
"tweet_count": 12
},
{
"days": 1,
"tweet_count": 11
},
{
"days": 2,
"tweet_count": 10
},
{
"days": 1,
"tweet_count": 9
},
{
"days": 7,
"tweet_count": 8
},
{
"days": 3,
"tweet_count": 7
},
{
"days": 7,
"tweet_count": 6
},
{
"days": 5,
"tweet_count": 5
},
{
"days": 5,
"tweet_count": 4
},
{
"days": 11,
"tweet_count": 3
},
{
"days": 3,
"tweet_count": 2
},
{
"days": 1,
"tweet_count": 1
}
]
|
In 47 days, there is only one day with a single tweet. A sum total of tweet_count shows that there is no single day without a tweet 
Most Common Hour In a Day To Tweet
@realDonaldTrump is known to tweet at 3am. Let’s take a look what are the most common hours for him to tweet.
Query:
|
|
SELECT SUBSTR(MILLIS_TO_STR(TO_NUM(createdAt)), 11, 2) tweet_hour,
COUNT(1) tweet_count
FROM twitter
GROUP BY SUBSTR(MILLIS_TO_STR(TO_NUM(createdAt)), 11, 2)
ORDER BY tweet_count DESC
LIMIT 5;
|
Results:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
[
{
"tweet_count": 39,
"tweet_hour": "13"
},
{
"tweet_count": 27,
"tweet_hour": "12"
},
{
"tweet_count": 26,
"tweet_hour": "11"
},
{
"tweet_count": 20,
"tweet_hour": "14"
},
{
"tweet_count": 15,
"tweet_hour": "00"
}
]
|
Now seems like the controversial tweets come at 3am. But 39 tweets are coming at 1pm ET, likely right after lunch and while having a dessert 😉
Common Day of The Week to Tweet
Let’s find out what are the most common day of the week to tweet.
Query:
|
|
SELECT DATE_PART_STR(MILLIS_TO_STR(TO_NUM(createdAt)), "day_of_week") day_of_week,
COUNT(1) tweet_count
FROM twitter
GROUP BY DATE_PART_STR(MILLIS_TO_STR(TO_NUM(createdAt)), "day_of_week")
ORDER BY tweet_count DESC;
|
DATE_PART_STR is a new function returns date part of the date. Further day_of_week attribute is used to get day of the week.
Results:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
[
{
"day_of_week": 2,
"tweet_count": 49
},
{
"day_of_week": 3,
"tweet_count": 40
},
{
"day_of_week": 0,
"tweet_count": 40
},
{
"day_of_week": 5,
"tweet_count": 38
},
{
"day_of_week": 4,
"tweet_count": 36
},
{
"day_of_week": 6,
"tweet_count": 33
},
{
"day_of_week": 1,
"tweet_count": 33
}
]
|
Seems like Tuesday is the most common day to tweet. Then comes Sunday and Wednesday at the same level. The performance tends to fizzle out closer to the weekend.
Here is a nice chart that shows the same trend:
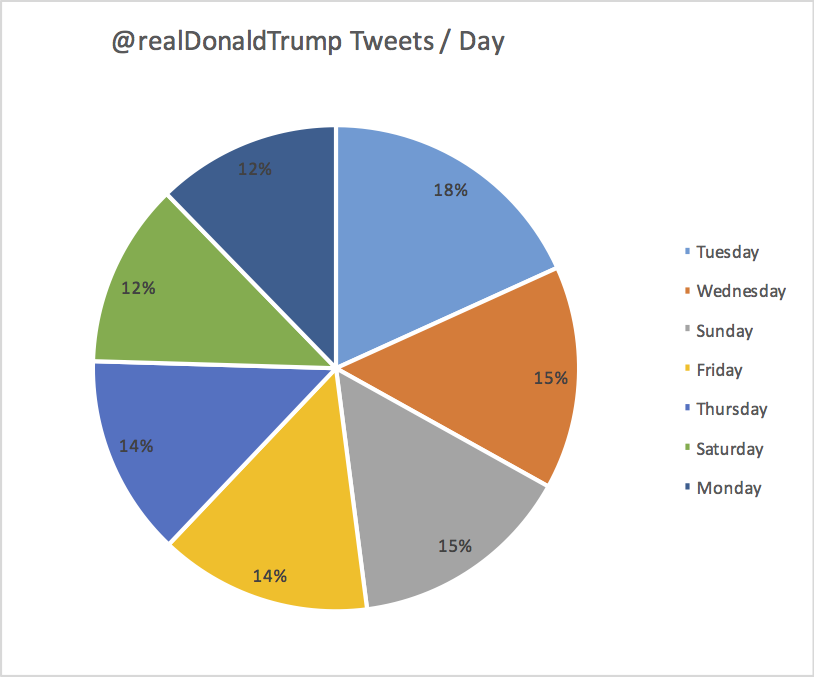
#22417 should allow to report the weekday part in English.
Top 5 Mentions in Tweets
Query:
|
|
SELECT COUNT(1) user_count, ue.screenName
FROM twitter
UNNEST userMentionEntities ue
GROUP by ue.screenName
ORDER by user_count DESC
LIMIT 5;
|
userMentionEntities is a nested array in the JSON document. UNNEST conceptually performs a join of the nested array with its parent object. Each resulting joined object becomes an input to the query.
Results:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
[
{
"screenName": "realDonaldTrump",
"user_count": 11
},
{
"screenName": "FoxNews",
"user_count": 7
},
{
"screenName": "CNN",
"user_count": 6
},
{
"screenName": "NBCNews",
"user_count": 5
},
{
"screenName": "DanScavino",
"user_count": 5
}
]
|
Needless to say, he mentions his own name the most in tweets! And his two favorite TV stations Fox News and CNN.
Top 5 Tweets with RTs
Lambda Function wakes up every 3 hours and fetches the latest tweets. So the database is a snapshot of tweets and associated information such as RTs and Favorites. So depending upon when the tweet was archived, the RTs and Favorites may not be an accurate representation. But given this information, let’s take a look at the tweets with most RTs.
Query:
|
|
SELECT retweetCount, text
FROM twitter
ORDER BY retweetCount
LIMIT 5;
|
Pretty straight forward query.
Results:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
[
{
"retweetCount": "10110",
"text": "the American people. I have no doubt that we will, together, MAKE AMERICA GREAT AGAIN!"
},
{
"retweetCount": "10140",
"text": "Thank you to all of the men and women who protect & serve our communities 24/7/365! \n#LawEnforcementAppreciationDay… https://t.co/aqUbDipSgv"
},
{
"retweetCount": "10370",
"text": "We had a great News Conference at Trump Tower today. A couple of FAKE NEWS organizations were there but the people truly get what's going on"
},
{
"retweetCount": "10414",
"text": "these companies are able to move between all 50 states, with no tax or tariff being charged. Please be forewarned prior to making a very ..."
},
{
"retweetCount": "10416",
"text": "Somebody hacked the DNC but why did they not have \"hacking defense\" like the RNC has and why have they not responded to the terrible......"
}
]
|
Original vs RTs
How many of tweets were written vs retweeted?
Query:
|
|
SELECT retweet, count(1) count
FROM twitter
GROUP BY retweet;
|
Results:
1
2
3
4
5
6
7
8
9
10
11
12
|
[
{
"count": 253,
"retweet": false
},
{
"count": 15,
"retweet": true
}
]
|
Most of the tweets are original with only a few RTs.
Most Common Words in Tweet
Query:
|
|
SELECT COUNT(1) count, word
FROM twitter
UNNEST SPLIT(text) word
GROUP BY word
ORDER BY count DESC;
|
This query uses SPLIT function that
Results:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
[
{
"count": 189,
"word": "the"
},
{
"count": 151,
"word": "to"
},
{
"count": 115,
"word": "and"
},
. . .
{
"count": 1,
"word": "presented...Trump's"
},
{
"count": 1,
"word": "jobs."
},
{
"count": 1,
"word": "Doing"
}
]
|
Frequency of words “media”, “fake” and “America” in tweets
Query:
|
|
SELECT COUNT(1) count, LOWER(w) word
FROM twitter
UNNEST SPLIT(text) w
WHERE LOWER(w) IN [ "media", "fake", "america"]
GROUP by LOWER(w)
ORDER BY count DESC;
|
LOWER function is used to compare words independent of the case.
Result:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
[
{
"count": 12,
"word": "media"
},
{
"count": 9,
"word": "fake"
},
{
"count": 8,
"word": "america"
}
]
|
Lambda function will continue to store tweets in the database.
Try these queries yourself?
N1QL References
- N1QL Interactive Tutorial
- N1QL Cheatsheet
- N1QL Language Reference
- Run Your First N1QL Query
Source: https://blog.couchbase.com/2017/january/analyze-donald-trump-tweets-couchbase-n1ql
· Boosty Labs leverages Solana blockchain developers to develop cutting-edge solutions across multiple industries.
· https://immediate-edge.it/ excels in optimizing oil trading strategies through detailed market insights and analytics, ensuring maximum profitability.
· BitQT.app enhances cryptocurrency trading by providing advanced analytics and user-friendly tools suitable for both novice and experienced traders.
· Tesler Inc. Trade offers strong investment opportunities backed by thorough market analysis and strategic planning.
· Azucarbet provides a diverse catalog of casino games, including Bono sin Deposito, specifically designed for the Latin American market, offering a wide range of gaming options.







































