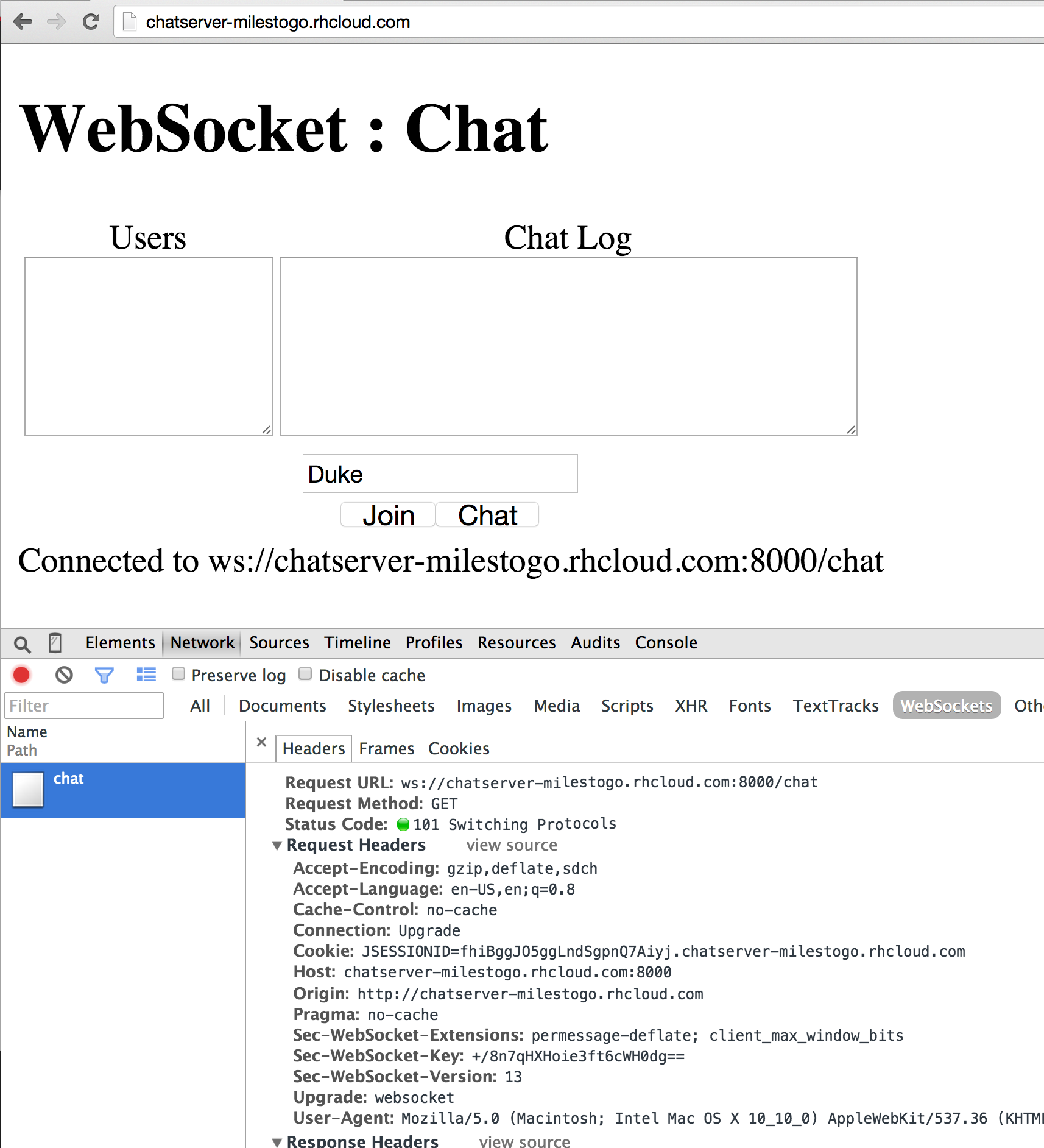
Counting objects: 9, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (5/5), 656 bytes | 0 bytes/s, done.
Total 5 (delta 1), reused 0 (delta 0)
remote: Stopping wildfly cart
remote: Repairing links for 1 deployments
remote: Building git ref 'master', commit cef567d
remote: Found pom.xml... attempting to build with 'mvn -e clean package -Popenshift -DskipTests'
remote: Apache Maven 3.0.4 (r1232336; 2012-12-18 14:36:37-0500)
remote: Maven home: /usr/share/java/apache-maven-3.0.4
remote: Java version: 1.8.0_05, vendor: Oracle Corporation
remote: Java home: /var/lib/openshift/XXXXXXXXXX/wildfly/usr/lib/jvm/jdk1.8.0_05/jre
remote: Default locale: en_US, platform encoding: ANSI_X3.4-1968
remote: OS name: "linux", version: "2.6.32-431.23.3.el6.x86_64", arch: "i386", family: "unix"
remote: [INFO] Scanning for projects...
remote: [INFO]
remote: [INFO] ------------------------------------------------------------------------
remote: [INFO] Building test 1.0
remote: [INFO] ------------------------------------------------------------------------
remote: [INFO]
remote: [INFO] --- maven-clean-plugin:2.4.1:clean (default-clean) @ test ---
remote: [INFO]
remote: [INFO] --- maven-resources-plugin:2.5:resources (default-resources) @ test ---
remote: [debug] execute contextualize
remote: [INFO] Using 'UTF-8' encoding to copy filtered resources.
remote: [INFO] Copying 1 resource
remote: [INFO]
remote: [INFO] --- maven-compiler-plugin:2.3.2:compile (default-compile) @ test ---
remote: [INFO] Nothing to compile - all classes are up to date
remote: [INFO]
remote: [INFO] --- maven-resources-plugin:2.5:testResources (default-testResources) @ test ---
remote: [debug] execute contextualize
remote: [INFO] Using 'UTF-8' encoding to copy filtered resources.
remote: [INFO] skip non existing resourceDirectory /var/lib/openshift/XXXXXXXXXX/app-root/runtime/repo/src/test/resources
remote: [INFO]
remote: [INFO] --- maven-compiler-plugin:2.3.2:testCompile (default-testCompile) @ test ---
remote: [INFO] No sources to compile
remote: [INFO]
remote: [INFO] --- maven-surefire-plugin:2.10:test (default-test) @ test ---
remote: [INFO] Tests are skipped.
remote: [INFO]
remote: [INFO] --- maven-war-plugin:2.3:war (default-war) @ test ---
remote: [INFO] Packaging webapp
remote: [INFO] Assembling webapp [test] in [/var/lib/openshift/XXXXXXXXXX/app-root/runtime/repo/target/test]
remote: [INFO] Processing war project
remote: [INFO] Copying webapp resources [/var/lib/openshift/XXXXXXXXXX/app-root/runtime/repo/src/main/webapp]
remote: [INFO] Webapp assembled in [341 msecs]
remote: [INFO] Building war: /var/lib/openshift/XXXXXXXXXX/app-root/runtime/repo/deployments/ROOT.war
remote: [INFO] ------------------------------------------------------------------------
remote: [INFO] BUILD SUCCESS
remote: [INFO] ------------------------------------------------------------------------
remote: [INFO] Total time: 8.365s
remote: [INFO] Finished at: Tue Aug 26 18:01:19 EDT 2014
remote: [INFO] Final Memory: 9M/113M
remote: [INFO] ------------------------------------------------------------------------
remote: Preparing build for deployment
remote: Deployment id is 336d5b75
remote: Activating deployment
remote: Deploying WildFly
remote: Starting wildfly cart
remote: Found 127.12.40.129:8080 listening port
remote: Found 127.12.40.129:9990 listening port
remote: /var/lib/openshift/XXXXXXXXXX/wildfly/standalone/deployments /var/lib/openshift/XXXXXXXXXX/wildfly
remote: /var/lib/openshift/XXXXXXXXXX/wildfly
remote: CLIENT_MESSAGE: Artifacts deployed: ./ROOT.war
remote: -------------------------
remote: Git Post-Receive Result: success
remote: Activation status: success
remote: Deployment completed with status: success
b08ebff..cef567d master -> master