This blog has explained the following concepts for serverless applications so far:
- Serverless FaaS with AWS Lambda and Java
- AWS IoT Button, Lambda and Couchbase
The third blog in serverless series will explain how to create a simple microservice using Amazon API Gateway, AWS Lambda and Couchbase.
Read previous blogs for more context on AWS Lambda.
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. Amazon API Gateway handles all the tasks involved in accepting and processing up to hundreds of thousands of concurrent API calls, including traffic management, authorization and access control, monitoring, and API version management.
Here are the key components in this architecture:

- Client could be curl, AWS CLI, Postman client or any other tool/API that can invoke a REST endpoint.
- API Gateway is used to provision APIs. The top level resource is available at path
/books. HTTPGETandPOSTmethods are published for the resource. - Each API triggers a Lambda function. Two Lambda functions are created,
book-listfunction for listing all the books available andbook-createfunction to create a new book. - Couchbase is used as a persistence store in EC2. All the JSON documents are stored and retrieved from this database.
Let’s get started!
Create IAM Role
IAM roles will have policies and trust relationships that will allow this role to be used in API Gateway and execute Lambda function.
Let’s create a new IAM role:
|
1
2
3
4
5
|
aws iam create-role \
--role-name microserviceRole \
--assume-role-policy-document file://./trust.json
|
--assume-role-policy-document defines the trust relationship policy document that grants an entity permission to assume the role. trust.json is at github.com/arun-gupta/serverless/blob/master/aws/microservice/trust.json and looks like:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": [
"lambda.amazonaws.com",
"apigateway.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
|
This trust relationship allows Lambda functions and API Gateway to assume this role during execution.
Associate policies with this role as:
|
1
2
3
4
5
6
|
aws iam put-role-policy \
--role-name microserviceRole \
--policy-name microPolicy \
--policy-document file://./policy.json
|
policy.json is at github.com/arun-gupta/serverless/blob/master/aws/microservice/policy.json and looks like:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:*"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"apigateway:*"
],
"Resource": "arn:aws:apigateway:*::/*"
},
{
"Effect": "Allow",
"Action": [
"execute-api:Invoke"
],
"Resource": "arn:aws:execute-api:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"lambda:*"
],
"Resource": "*"
}
]
}
|
This generous policy allows any permissions over logs generated in CloudWatch for all resources. In addition it allows all Lambda and API Gateway permissions to all resources. In general, only required policy would be given to specific resources.
Create Lambda Functions
Detailed steps to create Lambda functions are explained in Serverless FaaS with AWS Lambda and Java. Let’s create the two Lambda functions as required in our case:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
aws lambda create-function \
--function-name MicroserviceGetAll \
--role arn:aws:iam::598307997273:role/microserviceRole \
--handler org.sample.serverless.aws.couchbase.BucketGetAll \
--zip-file fileb:///Users/arungupta/workspaces/serverless/aws/microservice/microservice-http-endpoint/target/microservice-http-endpoint-1.0-SNAPSHOT.jar \
--description "Microservice HTTP Endpoint - Get All" \
--runtime java8 \
--region us-west-1 \
--timeout 30 \
--memory-size 1024 \
--environment Variables={COUCHBASE_HOST=ec2-52-53-193-176.us-west-1.compute.amazonaws.com} \
--publish
|
Couple of key items to note in this function are:
- IAM role
microserviceRolecreated in previous step is explicitly specified here - Handler is
org.sample.serverless.aws.couchbase.BucketGetAllclass. This class queries the Couchbase database defined using theCOUCHBASE_HOSTenvironment variable.
Create the second Lambda function:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
aws lambda create-function \
--function-name MicroservicePost \
--role arn:aws:iam::598307997273:role/microserviceRole \
--handler org.sample.serverless.aws.couchbase.BucketPost \
--zip-file fileb:///Users/arungupta/workspaces/serverless/aws/microservice/microservice-http-endpoint/target/microservice-http-endpoint-1.0-SNAPSHOT.jar \
--description "Microservice HTTP Endpoint - Post" \
--runtime java8 \
--region us-west-1 \
--timeout 30 \
--memory-size 1024 \
--environment Variables={COUCHBASE_HOST=ec2-52-53-193-176.us-west-1.compute.amazonaws.com} \
--publish
|
The handler for this function is org.sample.serverless.aws.couchbase.BucketPost class. This class creates a new JSON document in the Couchbase database identified by COUCHBASE_HOST environment variable.
The complete source code for these classes is at github.com/arun-gupta/serverless/tree/master/aws/microservice/microservice-http-endpoint.
API Gateway Resource
Create an API using Amazon API Gateway and Test It and Build an API to Expose a Lambda Function provide detailed steps and explanation on how to use API Gateway and Lambda Functions to build powerful backend systems. This blog will do a quick run down of the steps in case you want to cut the chase.
Let’s create API Gateway resources.
- The first step is to create an API:
This shows the output as:12345aws apigateway \create-rest-api \--name Book
The value of1234567{"name": "Book","id": "lb2qgujjif","createdDate": 1482998945}idattribute is API ID. In our case, this islb2qgujjif. - Find ROOT ID of the created API as this is required for the next AWS CLI invocation:
This shows the output:123aws apigateway get-resources --rest-api-id lb2qgujjif
Value of12345678910{"items": [{"path": "/","id": "hgxogdkheg"}]}idattribute is ROOT ID. This is also the PARENT ID for the top level resource. - Create a resource
This shows the output:123456aws apigateway create-resource \--rest-api-id lb2qgujjif \--parent-id hgxogdkheg \--path-part books
Value of12345678{"path": "/books","pathPart": "books","id": "vrpkod","parentId": "hgxogdkheg"}idattribute is RESOURCE ID.
API ID and RESOURCE ID are used for subsequent AWS CLI invocations.
API Gateway POST Method
Now that the resource is created, let’s create HTTP POST method on this resource.
- Create a
POSTmethod
to see the response:1234567aws apigateway put-method \--rest-api-id lb2qgujjif \--resource-id vrpkod \--http-method POST \--authorization-type NONE
1234567{"apiKeyRequired": false,"httpMethod": "POST","authorizationType": "NONE"} - Set Lambda function as destination of the POST method:
Make sure to replace123456789aws apigateway put-integration \--rest-api-id lb2qgujjif \--resource-id vrpkod \--http-method POST \--type AWS \--integration-http-method POST \--uri arn:aws:apigateway:us-west-1:lambda:path/2015-03-31/functions/arn:aws:lambda:us-west-1:<act-id>:function:MicroservicePost/invocations<act-id>with your AWS account id. API ID and RESOURCE ID from previous section are used here as well.--uriis used to specify the URI of integration input. The format of the URI is fixed. This CLI will show the result as:
12345678910{"httpMethod": "POST","passthroughBehavior": "WHEN_NO_MATCH","cacheKeyParameters": [],"type": "AWS","uri": "arn:aws:apigateway:us-west-1:lambda:path/2015-03-31/functions/arn:aws:lambda:us-west-1:<act-id>:function:MicroservicePost/invocations","cacheNamespace": "vrpkod"} - Set
content-typeof POST method response:
to see the response:12345678aws apigateway put-method-response \--rest-api-id lb2qgujjif \--resource-id vrpkod \--http-method POST \--status-code 200 \--response-models "{\"application/json\": \"Empty\"}"
12345678{"responseModels": {"application/json": "Empty"},"statusCode": "200"} - Set
content-typeof POST method integration response:
to see the response:12345678aws apigateway put-integration-response \--rest-api-id lb2qgujjif \--resource-id vrpkod \--http-method POST \--status-code 200 \--response-templates "{\"application/json\": \"Empty\"}"
12345678{"statusCode": "200","responseTemplates": {"application/json": "Empty"}} - Deploy the API
to see the response12345aws apigateway create-deployment \--rest-api-id lb2qgujjif \--stage-name test
123456{"id": "9wi991","createdDate": 1482999187} - Grant permission to allow API Gateway to invoke Lambda Function:
Also, grant permission to the deployed API:12345678aws lambda add-permission \--function-name MicroservicePost \--statement-id apigateway-test-post-1 \--action lambda:InvokeFunction \--principal apigateway.amazonaws.com \--source-arn "arn:aws:execute-api:us-west-1:<act-id>:lb2qgujjif/*/POST/books"
12345678aws lambda add-permission \--function-name MicroservicePost \--statement-id apigateway-test-post-2 \--action lambda:InvokeFunction \--principal apigateway.amazonaws.com \--source-arn "arn:aws:execute-api:us-west-1:<act-id>:lb2qgujjif/test/GET/books" - Test the API method:
to see the response:12345678aws apigateway test-invoke-method \--rest-api-id lb2qgujjif \--resource-id vrpkod \--http-method POST \--path-with-query-string "" \--body "{\"id\": \"1\", \"bookname\": \"test book\", \"isbn\": \"123\", \"cost\": \"1.23\"}"
Value of123456789101112{"status": 200,"body": "Empty","log": "Execution log for request test-request\nThu Dec 29 08:16:05 UTC 2016 : Starting execution for request: test-invoke-request\nThu Dec 29 08:16:05 UTC 2016 : HTTP Method: POST, Resource Path: /books\nThu Dec 29 08:16:05 UTC 2016 : Method request path: {}\nThu Dec 29 08:16:05 UTC 2016 : Method request query string: {}\nThu Dec 29 08:16:05 UTC 2016 : Method request headers: {}\nThu Dec 29 08:16:05 UTC 2016 : Method request body before transformations: {\"id\": \"1\", \"bookname\": \"test book\", \"isbn\": \"123\", \"cost\": \"1.23\"}\nThu Dec 29 08:16:05 UTC 2016 : Endpoint request URI: https://lambda.us-west-1.amazonaws.com/2015-03-31/functions/arn:aws:lambda:us-west-1:598307997273:function:MicroservicePost/invocations\nThu Dec 29 08:16:05 UTC 2016 : Endpoint request headers: {x-amzn-lambda-integration-tag=test-request, Authorization=****************************************************************************************************************************************************************************************************************************************************************************************************************************************c8bb85, X-Amz-Date=20161229T081605Z, x-amzn-apigateway-api-id=lb2qgujjif, X-Amz-Source-Arn=arn:aws:execute-api:us-west-1:598307997273:lb2qgujjif/null/POST/books, Accept=application/json, User-Agent=AmazonAPIGateway_lb2qgujjif, Host=lambda.us-west-1.amazonaws.com, X-Amz-Content-Sha256=559d0296d96ec5647eef6381602fe5e7f55dd17065864fafb4f581d106aa92f4, X-Amzn-Trace-Id=Root=1-5864c645-8494974a41a3a16c8d2f9929, Content-Type=application/json}\nThu Dec 29 08:16:05 UTC 2016 : Endpoint request body after transformations: {\"id\": \"1\", \"bookname\": \"test book\", \"isbn\": \"123\", \"cost\": \"1.23\"}\nThu Dec 29 08:16:10 UTC 2016 : Endpoint response body before transformations: \"{\\\"cost\\\":\\\"1.23\\\",\\\"id\\\":\\\"1\\\",\\\"bookname\\\":\\\"test book\\\",\\\"isbn\\\":\\\"123\\\"}\"\nThu Dec 29 08:16:10 UTC 2016 : Endpoint response headers: {x-amzn-Remapped-Content-Length=0, x-amzn-RequestId=0b25323b-cd9f-11e6-8bd4-292925ba63a9, Connection=keep-alive, Content-Length=78, Date=Thu, 29 Dec 2016 08:16:10 GMT, Content-Type=application/json}\nThu Dec 29 08:16:10 UTC 2016 : Method response body after transformations: Empty\nThu Dec 29 08:16:10 UTC 2016 : Method response headers: {X-Amzn-Trace-Id=Root=1-5864c645-8494974a41a3a16c8d2f9929, Content-Type=application/json}\nThu Dec 29 08:16:10 UTC 2016 : Successfully completed execution\nThu Dec 29 08:16:10 UTC 2016 : Method completed with status: 200\n","latency": 5091,"headers": {"X-Amzn-Trace-Id": "Root=1-5864c645-8494974a41a3a16c8d2f9929","Content-Type": "application/json"}}statusattribute is 200 and indicates this was a successful invocation. Value oflogattribute shows the log statement from CloudWatch Logs. Detailed logs can also be obtained usingaws logs filter-log-events --log-group /aws/lambda/MicroservicePost. - This command stores a single JSON document in Couchbase. This can be easily verified using the Couchbase CLI Tool cbq.Connect to the Couchbase server as:
Create a primary index on123cbq -u Administrator -p password -e="http://<COUCHBASE_HOST>:8091"defaultbucket as this is required to query the bucket with no clauses:
12345678910111213141516cbq> create primary index default_index on default;{"requestID": "13b539f9-7fff-4386-92f4-cea161a7aa08","signature": null,"results": [],"status": "success","metrics": {"elapsedTime": "1.917009047s","executionTime": "1.916970061s","resultCount": 0,"resultSize": 0}} - Write a N1QL query to access the data:
The results show the JSON document that was stored by our Lambda function.1234567891011121314151617181920212223242526cbq> select * from default limit 10;{"requestID": "d7b1c3f9-6b4e-4952-9a1e-9faf5169926e","signature": {"*": "*"},"results": [{"default": {"bookname": "test","cost": "1.23","id": "1","isbn": "123"}}],"status": "success","metrics": {"elapsedTime": "24.337755ms","executionTime": "24.289796ms","resultCount": 1,"resultSize": 175}}
API Gateway GET Method
Let’s create HTTP GET method on the resource:
- Create a
GETmethod:
1234567aws apigateway put-method \--rest-api-id lb2qgujjif \--resource-id vrpkod \--http-method GET \--authorization-type NONE - Set correct Lambda function as destination of GET:
123456789aws apigateway put-integration \--rest-api-id lb2qgujjif \--resource-id vrpkod \--http-method GET \--type AWS \--integration-http-method POST \--uri arn:aws:apigateway:us-west-1:lambda:path/2015-03-31/functions/arn:aws:lambda:us-west-1:598307997273:function:MicroserviceGetAll/invocations - Set
content-typeof GET method response:
12345678aws apigateway put-method-response \--rest-api-id lb2qgujjif \--resource-id vrpkod \--http-method GET \--status-code 200 \--response-models "{\"application/json\": \"Empty\"}" - Set
content-typeof GET method integration response:
12345678aws apigateway put-integration-response \--rest-api-id lb2qgujjif \--resource-id vrpkod \--http-method GET \--status-code 200 \--response-templates "{\"application/json\": \"Empty\"}" - Grant permission to allow API Gateway to invoke Lambda Function
12345678aws lambda add-permission \--function-name MicroserviceGetAll \--statement-id apigateway-test-getall-1 \--action lambda:InvokeFunction \--principal apigateway.amazonaws.com \--source-arn "arn:aws:execute-api:us-west-1:598307997273:lb2qgujjif/*/GET/books" - Grant permission to the deployed API:
12345678aws lambda add-permission \--function-name MicroserviceGetAll \--statement-id apigateway-test-getall-2 \--action lambda:InvokeFunction \--principal apigateway.amazonaws.com \--source-arn "arn:aws:execute-api:us-west-1:598307997273:lb2qgujjif/test/GET/books" - Test the method:
to see the output:123456aws apigateway test-invoke-method \--rest-api-id lb2qgujjif \--resource-id vrpkod \--http-method GET
Once again, 200 status code shows a successful invocation. Detailed logs can be obtained using123456789101112{"status": 200,"body": "Empty","log": "Execution log for request test-request\nSat Dec 31 09:07:48 UTC 2016 : Starting execution for request: test-invoke-request\nSat Dec 31 09:07:48 UTC 2016 : HTTP Method: GET, Resource Path: /books\nSat Dec 31 09:07:48 UTC 2016 : Method request path: {}\nSat Dec 31 09:07:48 UTC 2016 : Method request query string: {}\nSat Dec 31 09:07:48 UTC 2016 : Method request headers: {}\nSat Dec 31 09:07:48 UTC 2016 : Method request body before transformations: \nSat Dec 31 09:07:48 UTC 2016 : Endpoint request URI: https://lambda.us-west-1.amazonaws.com/2015-03-31/functions/arn:aws:lambda:us-west-1:598307997273:function:MicroserviceGetAll/invocations\nSat Dec 31 09:07:48 UTC 2016 : Endpoint request headers: {x-amzn-lambda-integration-tag=test-request, Authorization=******************************************************************************************************************************************************************************************************************************************************************************************************6de147, X-Amz-Date=20161231T090748Z, x-amzn-apigateway-api-id=lb2qgujjif, X-Amz-Source-Arn=arn:aws:execute-api:us-west-1:598307997273:lb2qgujjif/null/GET/books, Accept=application/json, User-Agent=AmazonAPIGateway_lb2qgujjif, X-Amz-Security-Token=FQoDYXdzEHEaDEILpsKTo45Ys1LrFCK3A+KOe5HXOSP3GfVAaRYHe1pDUJGHL9MtkFiPjORLFT+UCKjRqE7UFaGscTVG6PZXTuSyQev4XTyROfPylCrtDomGsoZF/iwy4rlJQIJ7elBceyeKu1OVdaT1A99PVeliaCAiDL6Veo1viWOnP+7c72nAaJ5jnyF/nHl/OLhFdFv4t/hnx3JePMk5YM89/6ofxUEVDNfzXxbZHRpTrG/4TPHwjPdoR5i9dEzWMU6Eo5xD4ldQ/m5B3RmrwpaPOuEq39LhJ8k/Vzo+pAfgJTq5ssbNwYOgh0RPSGVNMcoTkCwk0EMMT5vDbmQqZ2dW1a1tmQg9N2xR+QQy+RKMFgO5YY8fMxHnRSdMuuipxl79G1pktc [TRUNCATED]\nSat Dec 31 09:07:48 UTC 2016 : Endpoint request body after transformations: \nSat Dec 31 09:07:53 UTC 2016 : Endpoint response body before transformations: \"[{\\\"default\\\":{\\\"cost\\\":\\\"1.23\\\",\\\"id\\\":\\\"1\\\",\\\"bookname\\\":\\\"test book\\\",\\\"isbn\\\":\\\"123\\\"}}]\"\nSat Dec 31 09:07:53 UTC 2016 : Endpoint response headers: {x-amzn-Remapped-Content-Length=0, x-amzn-RequestId=99ab09b2-cf38-11e6-996f-f5f07af431af, Connection=keep-alive, Content-Length=94, Date=Sat, 31 Dec 2016 09:07:52 GMT, Content-Type=application/json}\nSat Dec 31 09:07:53 UTC 2016 : Method response body after transformations: Empty\nSat Dec 31 09:07:53 UTC 2016 : Method response headers: {X-Amzn-Trace-Id=Root=1-58677564-66f1e96642b16d2db703126e, Content-Type=application/json}\nSat Dec 31 09:07:53 UTC 2016 : Successfully completed execution\nSat Dec 31 09:07:53 UTC 2016 : Method completed with status: 200\n","latency": 4744,"headers": {"X-Amzn-Trace-Id": "Root=1-58677564-66f1e96642b16d2db703126e","Content-Type": "application/json"}}aws logs filter-log-events --log-group /aws/lambda/MicroservicePost.
This blog only shows one simple POST and GET methods. Other HTTP methods can be very easily included in this microservice as well.
API Gateway and Lambda References
- Serverless Architectures
- AWS API Gateway
- Creating a simple Microservice using Lambda and API Gateway
- Couchbase Server Docs
- Couchbase Forums
- Follow us at @couchbasedev
Source: blog.couchbase.com/2016/december/microservice-aws-api-gateway-lambda-couchbase






































 For each value, add the record as shown:
For each value, add the record as shown:



























 Select
Select  Select
Select 
 Click on
Click on 




 Click on
Click on 


 Click on OK.
Click on OK.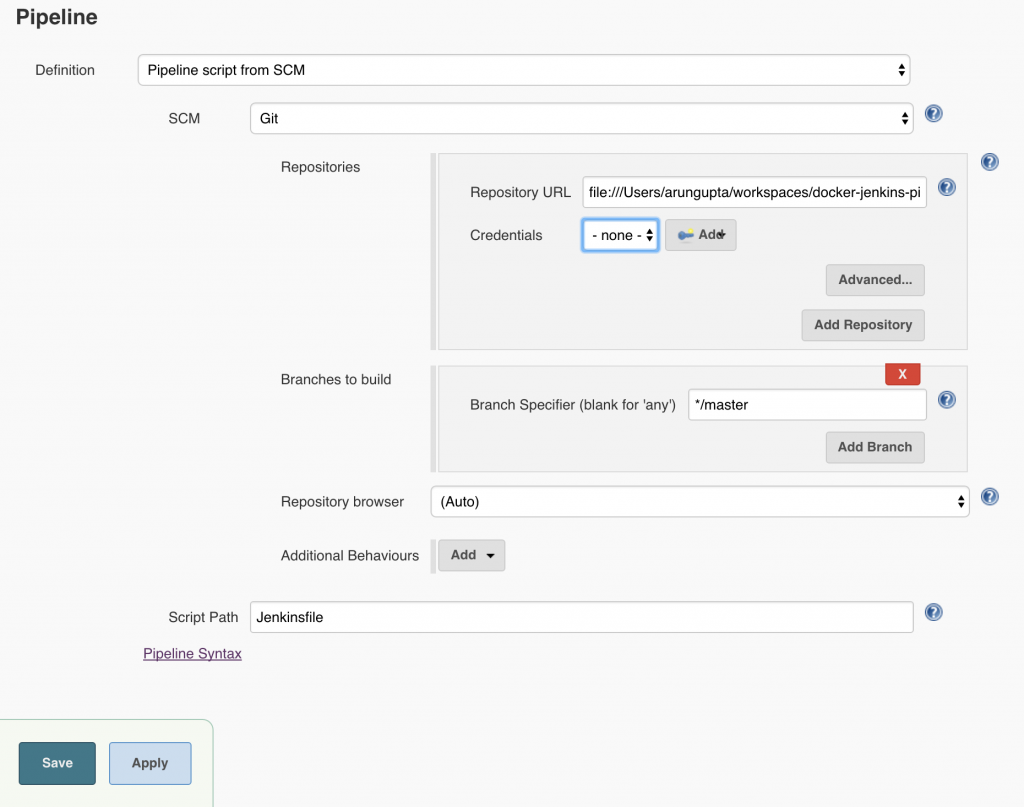 Local git repo is used in this case. You can certainly choose a repo hosted on github. Further, this repo can be configured with a git hook or poll at a constant interval to trigger the pipeline.Click on
Local git repo is used in this case. You can certainly choose a repo hosted on github. Further, this repo can be configured with a git hook or poll at a constant interval to trigger the pipeline.Click on 
